Intelligence Isn't the Moat Anymore: The New Frontier Is Verification
Intelligence Isn’t the Moat Anymore: The New Frontier Is Verification
TL;DR: AI isn’t progressing evenly. Jason Wei argues the real question isn’t when it changes everything, but which kinds of tasks it conquers first, and why verification, not intelligence, defines the next frontier.
A quant trader says ChatGPT can’t do his job. An AI researcher thinks she has 2-3 years before being replaced.
Who’s right?
Jason Wei (co-creator of o1 and Deep Research, 90k+ citations) thinks both are asking the wrong question.
The point isn’t when AI changes everything, but what, and in what order.
In a recent talk at Stanford, Wei presents three foundational principles for understanding AI’s trajectory. These principles move beyond the polarised debate between skeptics and believers to offer a predictive framework based on task properties we can identify today.
-
Intelligence as a Commodity: Once AI achieves a capability, its cost drops exponentially toward zero through adaptive compute and model efficiency improvements.
-
Verifier’s Law: AI’s ability to solve a task is directly proportional to how easily that task can be verified. Tasks with objective, fast, scalable, low-noise, and continuous verification will be conquered first.
-
The Jagged Edge of Intelligence: AI capabilities and improvement rates vary dramatically across tasks based on three heuristics: digital vs. physical, human difficulty level, and data abundance.
Key Implication: We won’t see a “fast takeoff” to superintelligence. Instead, expect highly uneven progress where some domains (software, research) accelerate dramatically while others (physical services, rare skills) remain largely untouched.
1. Intelligence as a Commodity. When Thinking Gets Cheap
Wei’s first principle tackles the price of thinking itself. Cognitive work (reasoning, retrieval, and problem solving) is becoming a commodity. Once an ability is unlocked by AI, its cost rapidly approaches zero.
Stage 1: Pushing the Frontier AI gradually unlocks new capabilities. Performance on benchmarks like MMLU improves incrementally as models scale and techniques advance.
Stage 2: Commoditisation Once a capability is achieved, the cost to access that level of intelligence decreases exponentially. Wei demonstrates this with MMLU benchmark data showing year-over-year cost reductions for equivalent performance. Each year, the cost of getting the same performance drops by orders of magnitude.
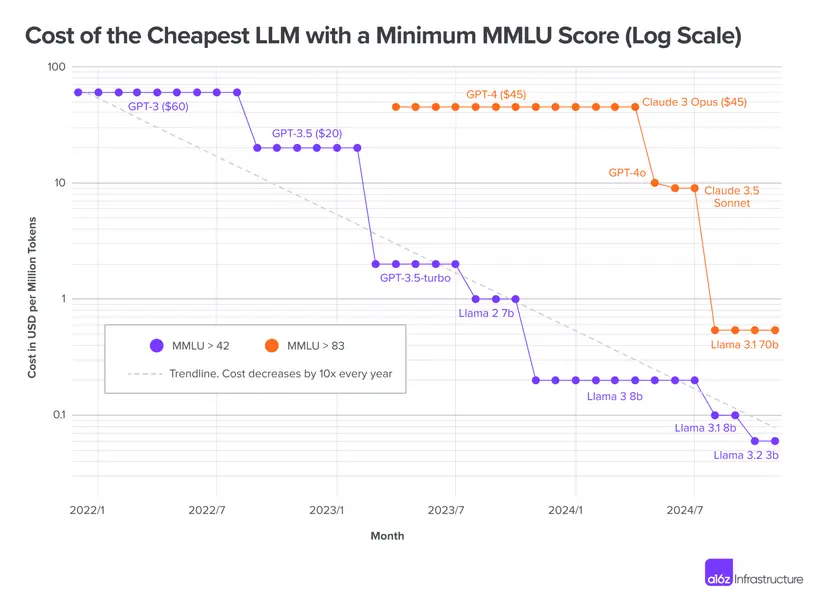
1.1. Information retrieval time collapse
Wei asks a simple question to make the point: “How many couples got married in Busan, South Korea in 1983?”.
Even more complex queries like “Of the 30 most populated Asian cities in 1983, sort them by number of marriages that year” previously took weeks. Now: minutes.
The shift isn’t about smarter models, it’s about how efficiently they spend their compute.
1.2. Technical inflection: Adaptive Compute
Adaptive compute is the game changer explaining why commoditisation will accelerate indefinitely.
Before, every problem used the same compute. “What’s the capital of California?” consumed the same resources as solving a competition math problem. This was wasteful and expensive.
Now, we can allocate 1 token to simple queries, 100,000 tokens to hard problems. OpenAI o1 demonstrated that increasing test-time compute on difficult problems improves performance proportionally.
Consequence: The cost of easy reasoning collapses without limit. We don’t need to scale model sizes indefinitely. Small, efficient models handle routine tasks while compute scales only where needed.
This is the first time in deep learning history that adaptive compute actually works at scale. It fundamentally changes the economics of intelligence.
1.3. Real-World Validation: BrowseComp Benchmark
OpenAI’s browsing competition benchmark tests questions that are easy to check but take humans hours to solve.
Eg: finding marriage statistics in Korean government database (KOSIS) requires navigating complex interfaces. OpenAI O3 couldn’t do this; OpenAI Operator can through autonomous browsing.
Deep Research now cracks about 50% of these problems. Many tasks that took most humans at least two hours were solved in minutes through autonomous agents.
1.4. Strategic Implications
-
Violent Democratisation of Knowledge-Gated Fields A talented high schooler with Cursor can now build what a 5-engineer team did in 2020. A biology undergrad with ChatGPT can access medical knowledge equivalent to a competent physician for biohacking experiments. Gatekeeping through knowledge is dead. What matters: taste, distribution, relationships, private data. Fields being democratised: Coding (Cursor, Windsurf, Replit), Research (literature review, synthesis), Personal health (biohacking, self-optimisation), Design (Figma + AI, v0), Writing and content creation.
-
Increased Relative Value of Private Information
When public information costs approach zero, private/insider information becomes disproportionately valuable, like:
- Off-market real estate deals
- Proprietary customer data
- Internal company metrics
- Network effects and relationships
- Exclusive access to people or places
The moat shifts from “what you know” to “what only you can know.”
-
Personalised Internet Experience
The shift from universal search results to AI-generated, personalised information interfaces. Instead of browsing a public internet, users will interact with dynamically generated, context-aware information environments tailored to their specific query and context.
2. Verifier’s Law: The Measure Becomes the Limit
If the first principle explains why reasoning gets cheap, this one explains why some reasoning improves faster than others.
The Verifier’s Law is a cousin of Goodhart’s Law: when a measure becomes a target, it reshapes the system itself (spoiler alert: it often ceases to be a good measure).
The Verifier’s law states that trainability of AI on a given task is proportional to how easy it is to verify success.
By corollary, any well-defined solvable, verifiable task, with unambiguous success criteria, will eventually be conquered by AI.
2.1. Understanding Asymmetry of Verification
Some problems are much easier to verify than to generate, and vice versa. This asymmetry is the key to predicting AI progress.

Verification asymmetry diagram Tasks can be plotted by ease of generation (x-axis) vs. ease of verification (y-axis). Adding privileged information (e.g. test cases, answer keys) can shift a task upward, making it easier to verify and therefore easier for AI to learn.

You can shift tasks upward by adding privileged information. Providing answer keys for math problems or test cases for code (as in SWE-bench) transforms moderately verifiable tasks into highly verifiable ones.
2.2. The Five Dimensions of Verifiability
Tasks are verifiable to the extent they possess these properties:
-
Objective Truth: Clear distinction between good and bad responses
-
Speed: Fast verification time
-
Scalability: Can verify millions of proposed solutions in parallel
-
Low Noise: Consistent results across verification attempts
-
Continuous Reward: Granular feedback beyond binary pass/fail
The more dimensions a task satisfies, the faster AI will master it.
Strategic implications
-
Automation Frontier is Verifiability Frontier: Tasks with trivial or automated verification are first to be fully solved.
-
Measurement as leverage: Designing measurable tasks and metrics becomes a central driver of AI progress and business defensibility. The company that can make an unverifiable task verifiable unlocks AI’s ability to solve it.
-
Recognising Unverifiable Domains: Some tasks will resist AI automation indefinitely because verification is fundamentally hard (long term outcome, high noise, subjective results, etc.)
3. The Jagged Edge of Intelligence: Why Progress Looks Uneven
If the first principle prices intelligence and the second measures it, the third describes its pattern of diffusion.
Technologies don’t spread evenly either; diffusion follows the same jagged logic: fast through digital networks, slow through physical supply chains.
AI progress is uneven and domain-specific, not a smooth march toward general superintelligence.
3.1. Rejecting Fast Takeoff Scenarios
Nick Bostrom in Superintelligence stated (and it’s now a popular belief) that once AI crosses a capability threshold, recursive self-improvement (RSI) will lead to rapid superintelligence.
Year 0: can’t train GPT n+1. Year 1: can train GPT n+1. Year 2: superintelligence.
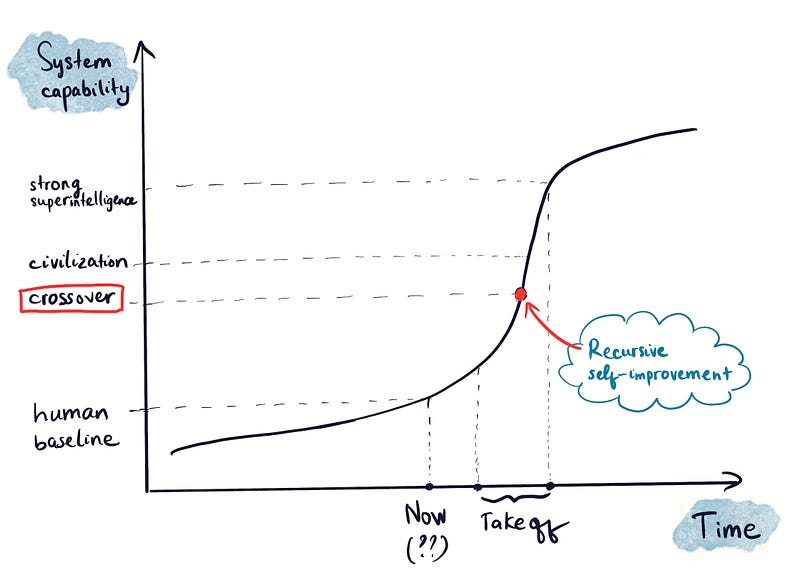
Wei argues that progress will be gradual and task-specific, not binary. A more realistic model would look like:
Year 0: Can’t even load the codebase autonomously Year 1: Can train something, results are mediocre compared to humans Year 2: Trains autonomously, but not as good as top 10 humans. Year 3 Mostly autonomous, occasional human intervention needed Year 4: Fully autonomous on some tasks, still needs humans on others etc.
And self-improvement happens at different rates: some tasks show rapid gains (math, code, search), others stagnate (rare languages, embodied action, social nuance). Each has a different “rate of improvement curve”.
3.2. Task-based improvement rates
Different domains evolve at different speeds due to: (i) verification ease, (ii), Data availability, and (iii) Digital / physical nature.
Each task has its own trajectory: peaks (fast progress) and valleys (stagnation).
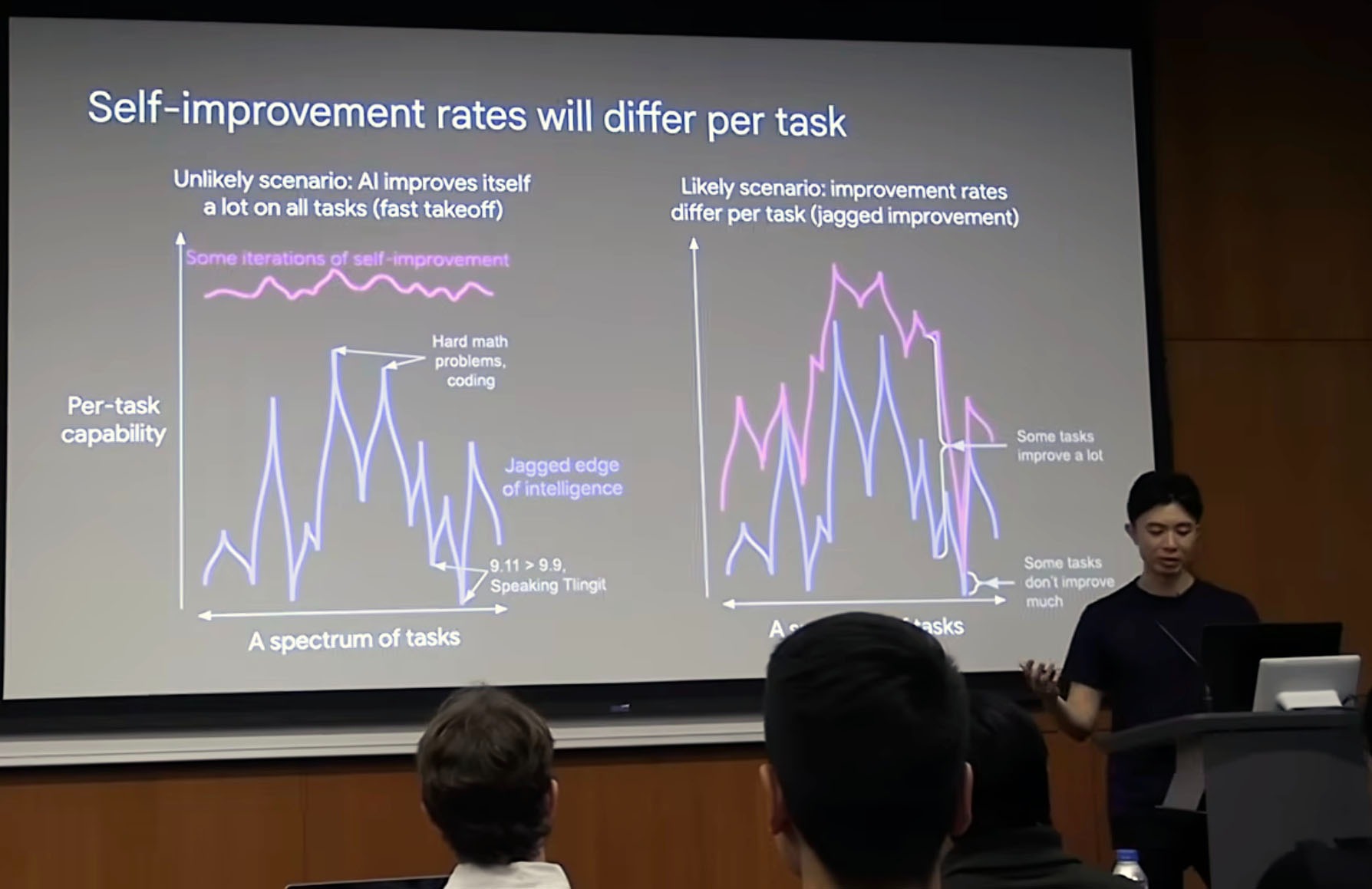
Heuristics for predicting improvement speed
-
Digital vs. physical: Digital tasks evolve faster due to higher iteration speed (rapid cycles, parallel testing), compute scalability (and safety concerns for physical tasks).
-
Human difficulty correlation: Tasks easy for humans are often easy for AI (important exceptions: tasks requiring scale or capabilities beyond human biology (analysing 10m images, maintaining consistency across millions of operations (and without fatigue or attention limits)
-
Data abundance: Performance correlates with available data volume (e.g. math in high-resource languages > low-resource).
-
Reward clarity: Tasks with explicit, measurable success signals accelerate via reinforcement learning.
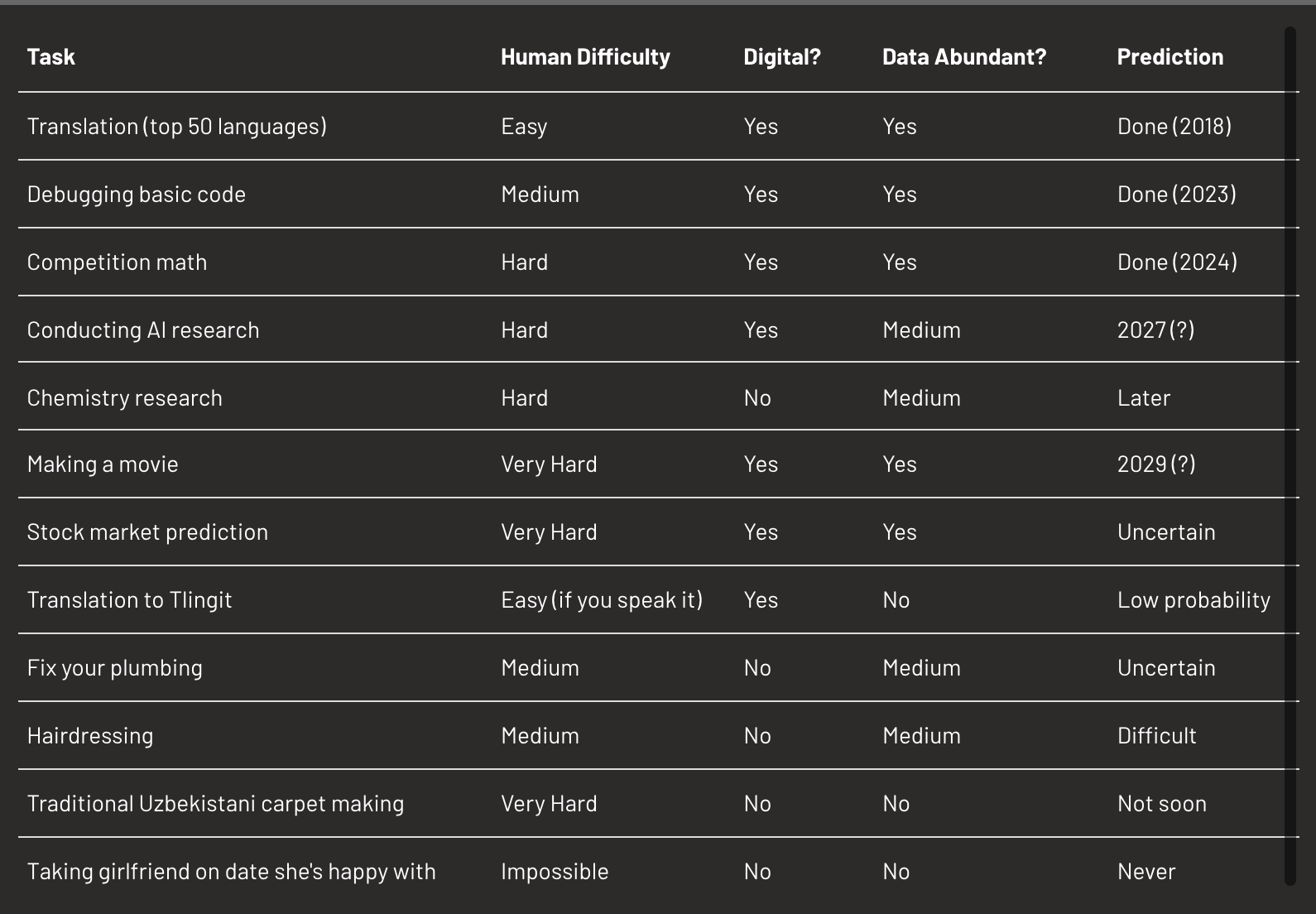
Macro implications:
-
Irregular capability curve: Some domains leap ahead, others remain static for decades.
-
Sectoral impact: Software development, data analysis, and content generation see rapid transformation; embodied and social work lags.
-
Self-improvement gradient: Each new capability expands locally before spreading across tasks. A model that gets better at Python doesn’t automatically get better at hairdressing. Progress is task-clustered, not universal.
Synthesis: The Three Gradients
Wei’s framework turns epistemology into strategy. The act of knowing isn’t scarce anymore; the act of confirming is. In that shift, verification becomes a new form of power.
The future won’t be uniformly transformative or uniformly disappointing. It will be specifically transformative based on task properties we can identify and predict.
Each gradient compounds over a different horizon, the timelines below show where they begin to bite.
Timelines by Gradient Position
Wei’s framework predict three gradients. Each company, field, or individual sits somewhere along them, and knowing where you stand might be the only durable edge left.
-
Short-term (1-3 years):
- Commoditisation of current capabilities (coding, analysis, writing).
- Emergence of AI-native companies in verifiable domains.
- Major productivity gains in digital knowledge work.
- Winner-take-most dynamics in newly automated fields.
-
Medium-term (3-7 years):
- Jagged progress creates massive arbitrage opportunities between peaks and valleys.
- Value accrues to measurement infrastructure and private data.
- Physical-world AI remains bottlenecked despite digital advances.
- Verification innovation unlocks new domains sequentially.
-
Long-term (7+ years):
- Intelligence costs → 0 for routine tasks.
- Human value shifts to unverifiable, relationship-based, or physical domains.
- Data moats and verification systems become core infrastructure.
- Jagged edge persists but shifts to different boundaries.
Wei’s framework doesn’t predict a single future but a moving frontier that depends on where measurement can reach.
The Critical Question
The question isn’t ‘will AI change the world’ but ‘where precisely are you positioned on these three gradients?’
If your business depends on (i) commoditisable intelligence (routine reasoning, knowledge retrieval), (ii) easily verifiable tasks (clear success metrics, automated testing), (iii) digital, data-rich domains (software, analysis, content), then you have probably 18-36 months to find a new moat, or you’ll disappear. The middle market in these domains is vanishing rapidly.
If you’re in the valleys (embodied physical work, rare data domains, unverifiable quality metrics, relationship-dependent services), you probably have several years if not decades before significant AI impact.
Your strategic advantage depends on accurately assessing where you sit on these three gradients and positioning accordingly. In the next decade, the bottleneck will shift from intelligence to instrumentation: whoever builds the better feedback loop wins.
Those who understand the jagged edge will capture asymmetric returns. Those who assume uniform progress will be caught off guard.
Intelligence won’t be the scarce resource of the next decade. Verification will.
“Intelligence and knowledge will be fast and cheap. Measurement will drive AI progress. The edge of intelligence is jagged.” Jason, Meta Superintelligence Labs (2025)
Article originally posted on WeLoveSota.com
